Merits of Defining your DB Schema in your Application?
Late last year I developed and released a Ruby plugin called
DrySQL that aims to eliminate any traces of DB schema re-definition in your application. The philosophy behind this effort is that the DB is indeed the place that table structures, constraints, and relationships should be defined, and that it is redundant to re-define any of these artifacts in an application or anywhere else.
While my colleagues in the enterprise space generally shared my philosophy, I have heard some suggest that
DrySQL's approach "sounded backwards" and I know of at least one project out there that aims to do exactly the opposite of what
DrySQL does: it aims to support defining the DB schema entirely on the application side rather than on the DB.
I don't yet understand the attraction of this approach, but I'll be interested to hear the opinions of those who support it. I have difficulty grasping the logic behind ignoring established best practices, no matter how small your business is, but I suppose that just about anything could make sense given the right (or wrong) set of requirements and restrictions.
In considering my case for the DB schema living on the DB and nowhere else, my goal is to satisfy 2 main concerns.
1) Controlling The Cost of ChangeTo
maximally reduce the cost of change in an environment consisting of one or more applications interacting with one or more databases, each database schema should be defined in one place only. If the schema is defined in more than one place, schema changes become more difficult (and thus more unattractive) to perform, as they must be cascaded across multiple definitions. If synchronizing multiple definitions requires human intervention, this approach is obviously prone to human error, not to mention tedium and annoyance. This situation is described as "inviting a maintenance nightmare" in The Pragmatic Programmer. Minimizing barriers to change is important to me because I want my software infrastructure to support evolution, and even encourage it.
2) Maintaining Data IntegrityGiven that the DB schema is to live in one place only, what place can guarantee the integrity of your data? Only the database itself. There are no back doors through the constraints defined on your database (except perhaps a bug in your DBMS if you are incredibly unlucky). Constraints defined elsewhere cannot be guaranteed to be enforced before data is written to your DB. Even in an environment where only one application interacts with your DB, it would be naive to think that your data would be safe without constraints on the DB. All it takes is one developer or tester (maybe even you?) to take a shortcut, execute a few "harmless" SQL queries through your database's command line interface (or any other interface for that matter), and your data is corrupted. The worst part of all is that the corruption might not be obvious immediately. Sure, an adequate backup schedule and a DB with some decent rollback/rollforward functionality will let you re-stabilize your data, but why pass up a frontline data protection mechanism that is so effective and accessible?
If you have an opinion on this subject -- particularly if it differs from mine -- please share it with me.
DB2 iSeries Adapter for Rails
I recently released a new version of
DrySQL (a Ruby plug-in) that supports DB2 iSeries. I didn't feel it was appropriate to post this on IBM's DB2 Rails Forum, so hopefully people who are interested in trying out this functionality will find this post.
iSeries is not currently supported by IBM's DB2 Rails adapter, so I created extensions to the IBM adapter and released them as part of DrySQL. As far as I know, this is the only generally available iSeries adapter for Ruby at the moment. Those who do not care to use the DrySQL plug-in can simply unpack the gem, pull out the DB2 adapter extensions, and use them however they wish to. I expect to add the code to the DrySQL SVN repository on RubyForge shortly, which should make this easier.
Note that you will need to install DB2 Connect and the IBM DB2 Rails adapter in order to use this functionality.
You can find more information about this on the
DrySQL homepage. If anyone needs help getting it up and running or wants to report bugs, please reply to this post and/or post to the
DrySQL forums on RubyForge.
Update (May 29, 2007):IBM's ibm_db adapter now supports iSeries, so I have removed the custom support from DrySQL. The latest code from the DrySQL SVN repository on RubyForge works correctly with the ibm_db adapter.
Labels: database, drysql, ruby-smalltalk
Multiple Cascade Paths Error in SQL Server
Working on
DrySQL has given me an opportunity to learn about the subtle differences between many DBMSs.
As my project is designed to run on a number of DBMSs, I crafted a reasonably complex test DB schema that I create on each DBMS in order to run my unit tests.
Though my test schema can be created without error on MySQL, PostgreSQL, and DB2, when I attempted to create it on SQL Server Express 2005 recently, it errored on the attempted creation of a FOREIGN KEY constraint with cascaded deletes and updates:
Server: Msg 1785, Level 16, State 1, Line 1 Introducing FOREIGN KEY constraint 'PAYMT_APP_FK2' on table 'PAYMENT_APPLICATION' may cause cycles or multiple cascade paths. Specify ON DELETE NO ACTION or ON UPDATE NO ACTION, or modify other FOREIGN KEY constraints. Server: Msg 1750, Level 16, State 1, Line 1 Could not create constraint. See previous errors.
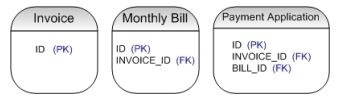
I'll explain the error using the following table layout.

Note that all the FOREIGN KEYs were created with cascaded delete and update options.
The constraint definition that produced the error above was in my
CREATE TABLE statement for the
PAYMENT_APPLICATION table.
[PAYMENT_APPLICATION.BILL_ID...]FOREIGN KEY REFERENCES MONTHLY_BILL.ID CASCADE DELETE CASCADE UPDATE
According to
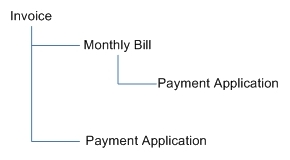
Microsoft the above error occurs because "a table cannot appear more than one time in a list of all the cascading referential actions that are started by either a DELETE or an UPDATE statement". So, my constraint definition produces an error because the cascading delete path for INVOICE would like this if the constraint were defined:
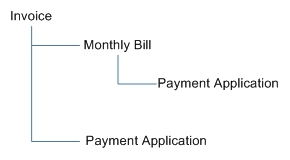
My
PAYMENT_APPLICATION table will appear twice on
INVOICE's cascading delete/update path:
PAYMENT_APPLICATION has an FK reference to INVOICE with cascading delete/update options
PAYMENT_APPLICATION has an FK reference to MONTHLY_BILL with cascading delete/update options, and MONTHLY_BILL has an FK reference to INVOICE with cascading delete/update options
As I mentioned earlier, SQL Server stands alone (to my knowledge) as the only DBMS that considers such constraints to be illegal. A simple solution to my problem would be to remove the cascade options from my
PAYMENT_APPLICATION-->INVOICE Foreign Key constraint. The deletion/update of a referenced
INVOICE or
MONTHLY_BILL will still trigger a cascade onto the related
PAYMENT_APPLICATION record, which is ultimately the behaviour that I want.
I can still create a DB schema that meets my needs in SQL Server, but it's annoying that I need to define my constraints differently than I do with other databases (although fairly typical of Microsoft software). I can't help wondering if this is a feature or a limitation.
If anyone else has an opinion about this, I'll be interested to hear it.
...And if anyone else experiences this error and struggles to figure out why, hopefully you find this explanantion helpful.
Labels: database
Generating ActiveRecord Data Validations Automatically
Having recently released
DrySQL, which automatically generates validations for ActiveRecord data classes that enforce the constraints declared on your DB, I thought it might be useful to start a discussion about how this works (or should work).
My (possibly naive) belief is that the value of application-side validations that enforce DB constraints is twofold:
- Allows the application to provide immediate feedback to UI/forms/whatever about validity of input without the performance overhead of querying the DB
- Avoids wasting application and DB cycles trying to save/update invalid records
That said, let's look at the ActiveRecord validation methods, how they apply to enforcing DB constraints, and how
DrySQL generates them automatically.
validates_uniqueness_of
I don't understand how this validation is useful, but will be interested to hear others' opinions about it. To validate that a particular value is unique in a particular table requires a DB query. Why do this on the application side rather than just letting the DB perform the validation and handling the duplicate key error your DB returns? This validation can be generated automatically based on the unique key information in the DB's information schema, but I'm not sure that it should be.
validates_length_ofvalidates_numericality_ofThese validations can be generated automatically by querying the information schema's columns table. The columns table contains the restrictions that were declared for the column when it was defined.
validates_inclusion_ofvalidates_exclusion_ofThese validations can be generated automatically for databases that support check constraints, but
DrySQL does not yet implement this. Currently,
validates_inclusion_of is generated automatically only for boolean columns since we know the value must be in the set [true, false].
validates_presence_ofThis validation can be generated automatically by querying the information schema's columns table and checking the column's NOT NULL constraint. Unfortunately, the implementation of this validation in ActiveRecord does not accurately mirror the DB's NOT NULL constraint. In situations where the column contains character data and has the NOT NULL constraint set,
validates_presence_of will reject an empty string value even though the DB would consider this value to be valid.
DrySQL does not generate this validation, but rather generates a new validation,
validates_nullability_of, where appropriate.
validates_nullability_ofThis constraint is new, and was developed as part of
DrySQL. It mirrors your DB's handling of NOT NULL constraints. This validation will reject a null value unless the column is autogenerated or has a default value specified, because your DB wouldn't reject a NULL in these situations either.
Labels: database, drysql, ORM, ruby-smalltalk
DrySQL: Answering the Challenge
After developing
DrySQL to support some DB tooling at the financial organization that employs me, I was happy to learn that the functionality provided by
DrySQL is actually the subject of Dave Thomas's (of Pragmatic fame) challenge to the Rails community at RailsConf 2006.
The video of the keynote is available
here.
Leon Katsnelson, who is involved with the development of the official
IBM Rails DB2 adapter, has also expressed the desire for this functionality on the DB2onRails blog
here.
Leon and Dave, if you ever happen to visit my blog or come across
DrySQL somehow, I will be interested to hear your feedback about it.
Labels: drysql
Introducing DrySQL
After complaining about Object-Relational Mapping frameworks for years, I finally decided to do something about it.
The ProblemMy primary problem with today's ORM frameworks is that I end up defining my DB schema
twice: once on my DB itself, and once again in my application either in class definitions or ORM config files. Obviously, if I make structural changes to my DB I need to make corresponding changes in my application code or config files. I know that there are round-trip engineering solutions out there, as I mentioned in
my previous ORM rant, but I have yet to come across a solution that I consider clean, efficient, simple, or remotely DRY (I would be interested in hearing about some though).
The Solution: ActiveRecord?After experimenting with ActiveRecord and Ruby, I became convinced that I was onto something.
Mapping Classes to Tables & Instvars to ColumnsActiveRecord does the work of mapping classes to tables and instance variables to columns dynamically. If I change the columns in my table, my ActiveRecord-enabled app picks up these changes on restart. This is a step in the right direction (for my needs).
AssociationsActiveRecord also provides support for developer-specified associations, which are basically smart accessor methods on your class that will retrieve associated objects through join queries.
ValidationsLastly, ActiveRecord provides support for developer-specified validations, which are basically application-side enforcement of DB constraints. These are useful for providing feedback to a UI without querying the DB (and taking a performance hit for DB I/O, and wasting DB cycles).
What's Missing?ActiveRecord is fantastic (I might go so far as to call it groundbreaking), but unfortunately it doesn't quite meet my needs. AR makes assumptions about naming conventions for tables, primary keys, foreign keys, and breaks down in numerous situations when the DB schema is complex.
AR does provide support for explicitly declaring my table names, keys, etc., but I have a fundamental problem with declaring these things in my application code when they are already declared in my DB schema. As well, I don't want to write code to specify relationships between DB records or constraints on them, as I have already done this on my DB itself.
DrySQLDrySQL is an extension to ActiveRecord that provides a truly DRY Object-Relational Mapping solution. As long as DrySQL is able to map your class to a table (either using AR naming conventions, or a call to set_table_name inside your class definition), you need not define any properties of your table. DrySQL will query the DB's information schema and automatically identify keys & constraints, and generate your class's associations and validations. It then delegates the instvar-column mapping duties to ActiveRecord. The result is that all the Object-Relational Mapping logic is abstracted away from your application, and is completely dynamic. Any changes you make to the structure and behaviour of your DB are dynamically picked up by your application at startup.
DrySQL doesn't make assumptions about your naming conventions, or the nature of your application (Rails web app, Ruby desktop, etc). As a result, "legacy" DB tables can get the benefit of DrySQL's ORM magic, and DrySQL can be used in any Ruby application.
If you do have the freedom to follow ActiveRecord's naming conventions in your DB, there is no need to even define your data classes. DrySQL will generate them in memory the first time you reference them. And then it will generate the associations and validations, and identify the keys and constraints the first time you create an instance of your class.
What this means is that you can ditch all the code you write today to map, describe, and constrain DB data in your application.
I will dig into the gory details of how DrySQL works in subsequent posts, but in the meantime please check out the
DrySQL project homepage on RubyForge for more details about the features of DrySQL, how to use it, and how to download it.
Labels: database, drysql, ORM, ruby-smalltalk
Some Interesting MySQL facts
I've been doing a lot of research into the internals of MySQL in order to develop DrySQL, and here are some useful bits of information that I came across:
1) Check constraints are not supported in the latest version of MySQL (5.1.x). The syntax for check constraints is supported, but any check constraints in your alter/create table syntax are just ignored.
Official MySQL documentation.
2) The REFERENTIAL_CONSTRAINTS table was added to the INFORMATION_SCHEMA database as of MySQL 5.1.10.
Bug Report/Feature Request
Official MySQL documentation
This is in compliance with the ISO SQL:2003 standard. This table is useful to those who want information about the "ON UPDATE" and "ON DELETE" rules associated with a table constraint. Currently, the only solution for retrieving this info is to parse the SHOW CREATE TABLE output, which is a pretty ugly hack and a performance hit compared to retrieving the constraint info directly from the INFORMATION_SCHEMA DB.
3) MySQL creates implicit default values for columns if no default is specified. If the column is nullable, then MySQL sets the default value to NULL. If the column is not nullable, the default is value is set the MySQL's implicit default value for that column type (check this link for details about implicit defaults).
Suppose I create the following table:
CREATE TABLE TEST (ID CHAR(11) NOT NULL)
If I query the information schema's COLUMNS table to find out whether a default value has been specified for the ID column in the TEST table, MySQL will return to me the empty string as the default value. Does this mean that the empty string was defined as the default value for this column, or that no default was specified at all? Unfortunately, there is no way to make this determination in the latest version of MySQL, which is a pain for those of us developing DB tools against MySQL.
Errata: As of version 5.0.2, MySQL no longer creates implicit default values when no default is specified
4) Roland Bouman created an excellent clickable diagram of the MySQL Information Schema, which can be found here.
Labels: database, mysql